Why I Blog and How I Automate it
# Why I Blog
I’m interested in consuming information in order to create new information (one of my motivations for pursuing a Ph.D.). I generally read articles/papers or watch videos, and then create papers/articles/code and have discussions as a result. While creating blog posts could be considered ‘giving back’, I think most of the benefit is personal because it (if well-written) forces me to make sense of and distill the ideas therein sufficiently such that someone else can understand me, which requires confronting various weaknesses and problems with the idea and improving on them (This is also one reason why I believe feedback systems are important).
Other sources refer to this as the Knowledge Lifecycle, of which I’ve included a screenshot below (the image comes from A Complete Guide to Tagging for Personal Knowledge Management (
link) — they do a great job explaining this idea in detail which I won’t repeat).
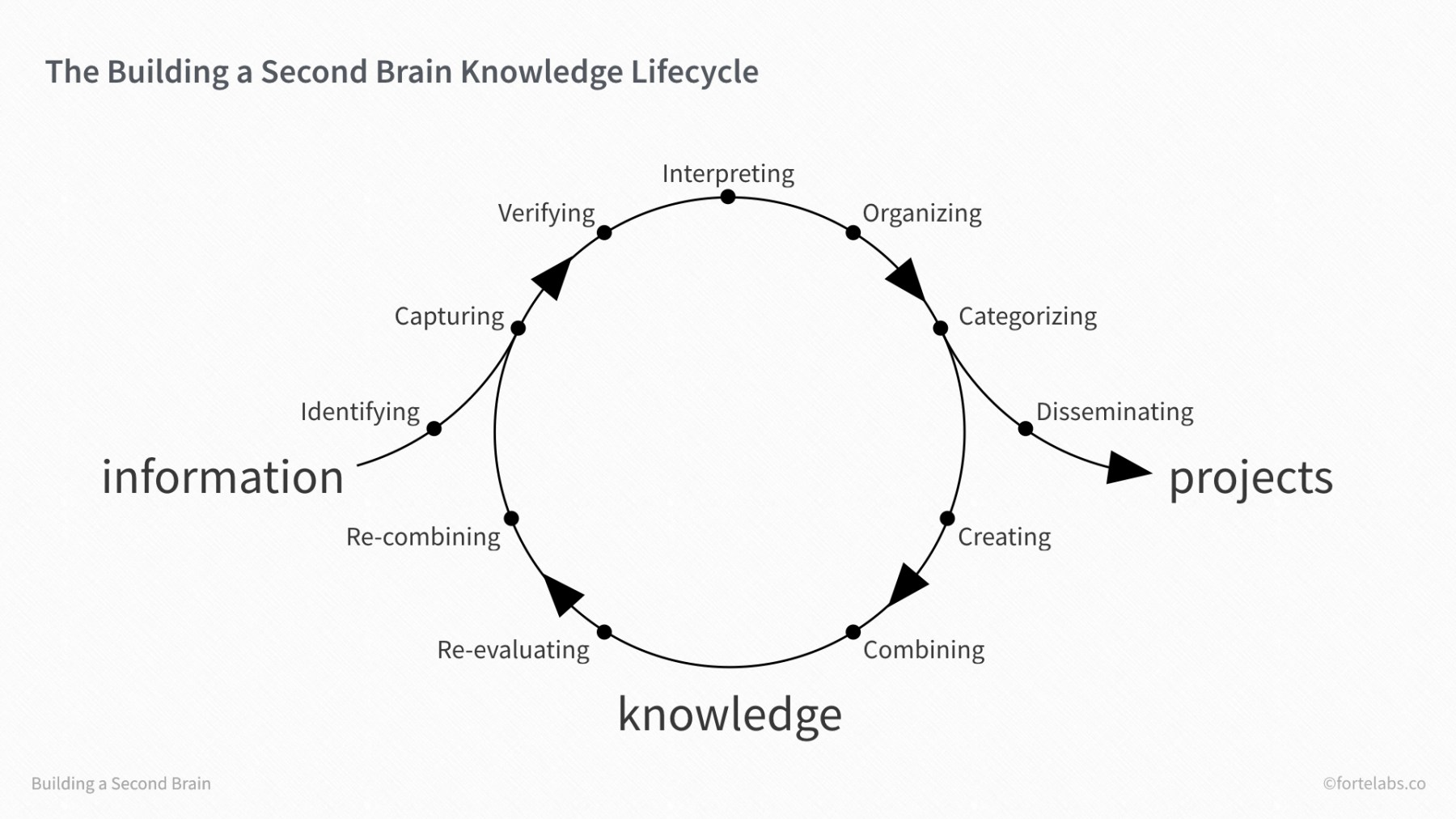
My Markdown-based Personal Knowledge Management (PKM) notes system, which I’ve been building for years and currently interact with using Obsidian, is a grounds for this. In a nutshell, this is my process:
- Organize how I ingest new knowledge. I usually learn from articles/blogs/papers/videos online and sometimes learn from books as well, but all of these, even finding out about said book, originate from a browser tab. I maintain different sets of browser tabs for different research areas in both work and personal pursuits and organize these using tools such as the awesome BrainTool and sometimes Obsidian. After writing this post, I created a read-it-later solution for this.
- Any high-quality paper/article/video/etc. I read and want to remember goes into Zotero and synced between laptops/desktops via Syncthing (and is annotated there for PDFs only) (#todo write a post on link rot and my interest in preserving digital information)
- Said annotations and links to the local Zotero file+URL are synced into Obsidian as a paired ‘Source’ note for whenever I want to write additional things regarding that source of information (via plugin Obsidian-Zotero Integration)
- Non-Source notes in my PKM system are all my own writings and ideas which I often build off of Sources and their corresponding Source Notes using Markdown links and embeds (though sometimes I lazily skip this and just cite URLs)
- A few of these notes become well-developed and useful (meaning useful even after they are written—I still think the act of writing itself forces the writer to clarify certain concepts and is useful even if the writing itself isn’t used again)
- A few useful notes seem interesting enough that I think others may benefit from them, so I spend time improving the prose, generalizing them, etc., and create a blog post.
Out of 100 saved papers/articles, ~20 will have source notes, ~10 of those source notes lead to my own independent idea notes, ~4 of them become well-developed and useful, and just 1 gets turned into a blog post.
The problem with my previous site setup was that while all of my knowledge (from other sources or from me) was stored in my tightly-integrated Zotero+Obsidian setup (steps 1-4 above), step 5’s blog posts containing in principal my highest-quality technical assimilations of knowledge were disjointly stored in the site’s repository. I’d like to have everything in one place so it is all easily searchable and linkable and therefore give me greater opportunities to make new connections between my ideas and other sources’ ideas. Sure, I can just have multiple copies of the posts, but heaven forbid I have to correct that missed typo in two places. (Though in all seriousness, I wanted to eliminate any friction that would discourage me from publishing new content or improving existing posts.)
Thus, I wanted to find a way to better integrate all of my knowledge in one place and also seamlessly publish blog entries to increase the chances of me actually doing so. I may stop using the term ‘blog’ in the future as I expect to update and improve these posts the same way I improve my own private notes (or ‘posts’).
# How I Automate it
I often spend far too many hours building or automating things that have perfectly reasonable alternatives, because I find it fun to understand and control every step of the process (and on some rare occasions it becomes objectively useful as well). I’ve done this with my blog in my 2023 redesign—while I could have easily made an account on https://substack.com/, I prefer to have total control over the look and feel of the site (e.g., no annoying popups to subscribe after reading 1/4 down the article) and already had a simpler custom blog since 2019.
When I first acquired the domain ryanwwest.com, I had a Wordpress site for about a month and got very sick of it. I quickly decided instead to make a static site instead by just placing HTML/CSS/JavaScript files on my hosting server, but since I am much more proficient at backend/network software engineering than frontend, I didn’t want to open the door of endless JavaScript frameworks and instead opted to use the Markdown->static site generator Hugo.
Hugo works great because I already heavily use Markdown via Obsidian for my PKM system. However, Hugo on its own turned out to be insufficient for my needs, as I only have time to write a blog post very irregularly, and had to remember how to rerun the site generator, log into site server, and publish the new article every time which disincentivized publishing. Any changes to a blog post required repeating the process and the articles were disjoint from the rest of my knowledge base, and I don’t want any friction.
Hugo can be customized with
themes, and I chose the
Quartz Theme which adds goodies like [[Wikilink]] support, search, backlinks, local graph view, dark/light mode toggle, etc. However, while this brings Markdown-style parity between blog post notes and all other notes to be nearly the same, it still doesn’t automate the publishing of posts (and I don’t want to pay $20 a month for something like
Obsidian Publish).
Thus, I’ve automated it as follows:
- On any device using Obsidian, Vim, or another file editor, I create a blog post in its own Markdown file witin the
blog/subdirectory of my PKM vault. - I have a Linux server and sync my PKM vault folder between it and my other computers/devices using Syncthing.
- My Linux server runs a
cron job every minute which runs a
script that scans the
blog/subdirectory to get lists of all Markdown files and png/jpg files they link to (which are stored not inblog/, butmedia/with all other non-blog attachments), usesrsyncto copy them over to my Hugo directory, and generates the Hugo site based on just those copied files (it excludes Markdown files that are drafts, but I have a ‘staging’ version of my site including drafts available on that server that I can access via my Tailscale personal-only VPN). - The same cron job also commits just the public HTML output folder of Hugo to a Git repo (if there are changes) and pushes to GitHub.
- On my site provider’s Linux server, I run another cron job which periodically tries to pull the same Git repo for changes. Because the repo is just the public HTML, ryanwwest.com just points that repo for the entire site’s HTML/CSS/JavaScript. If I edit a blog post note from Obsidian on any device, it should be live within a few minutes.
# Blog Comment System
I wanted a comment system for my posts as well to allow for generative conversation between myself and interested readers, but didn’t want to host it myself (because more expensive to run, have to deal with spam and a login system, etc.). That disqualified seemingly great self-hosted options like Isso and Discourse, and I didn’t want something proprietary like Disqus which injects its own ads. Hypothesis seems extremely neat for a blog comment system (and technically already exists for every site, but you can fully integrate it without needing a browser extension), but issues include lack of comment moderation (individuals cannot easily make Publisher Groups which allow this), a confusing/unfamiliar interface for post-wide comments (comments that are not specific to a certain line of text in the post), and no comment upvoting system. But I’m keeping an eye on this one. Graham Macphee use Mastodon for blog comments which is neat, but too early for me.
What I instead chose was giscus. It uses a GitHub repo’s Discussions feature to give users an almost Reddit-like commenting experience where one Discussion is automatically created for every post. A snippet of JavaScript at the end of this page embeds the comments on the associated GitHub discussion and lets anyone read comments directly on this page, and lets readers with GitHub accounts also comment directly on on this page (or on GitHub). Discussion comments support Markdown and images, reactions, threaded replies, upvoting, and can be sorted by most upvotes/oldest/newest. The biggest problem is that it is dependent on GitHub (including requiring commenters to have a GitHub account), though sorting by top comments also isn’t yet supported directly on the blog page. Since I presume most of my readers are technical, I’m not too concerned about these, but would switch to something else if a better alternative came along. Easily commenting/annotating specific parts of the post might also be nice, as Hypothes.is allows, but this can be partially satisfied with quotes.
- Great source of ideas for other commenting systems: https://darekkay.com/blog/static-site-comments/
- Great post advocating comments within blogs: https://blog.codinghorror.com/a-blog-without-comments-is-not-a-blog/
# Future Improvements
I’d like to have a way to hide certain ‘personal comment’ lines within a blog post’s Markdown file that may contain helpful information for the author but not for readers (like links to other non-blog notes). I specifically left in a #todo ‘comment’ above to illustrate how this was unnecessary for the reader to see, but helpful for me in that context.
Being able to instantly write and edit blog posts is both a blessing and a curse. A curse, because if I accidentally change a file on any device anywhere, that modification rapidly goes live. Not really a big deal for a small personal blog, but maybe it will come back to bite. (Accidental deletes, on the other hand, are not a problem because rsync doesn’t delete in this case - I must manually remove them, which is only annoying for filename changes)
I’d also like for the table of contents to hover to the left of the main article column when the browser aspect ratio allows it, rather than being pinned to the top of the page.
I have a YouTube channel with just one video (as of 2023-03-22). That may be another good medium for posting future technical content and may be easier and more accessible for content consumption.